モバイルコンテンツの操作性を飛躍的に向上させるソリューション
株式会社アドバンスト・メディア〈東京都豊島区、代表取締役社長:鈴木清幸、以下アドバンスト・メディア〉は、携帯電話コンテンツに音声認識機能を付与できる『AmiVoice(R) DSR for Mobile Contents』のサービスを開始します。すでに販売されている本体のみで音声認識を行う携帯電話では不可能であった、高精度大規模語彙の音声認識を可能とし、本サービスを利用したコンテンツを作成することにより、携帯電話に向かって話すだけで、住所/駅名/ランドマークなどがコンテンツに入力できるようになります。『AmiVoice(R) DSR for Mobile Contents』は、コンテンツの付加価値を飛躍的に向上させるサービスです。
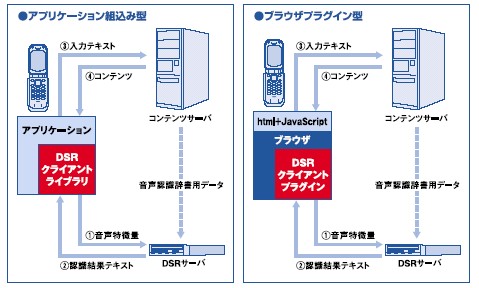
『AmiVoice(R) DSR』は、携帯端末に当社が開発したAmiVoice(R) DSR Client、サーバ側にAmiVoice(R) DSR Serverを実装して分散処理を行うことで、携帯電話に負担をかけずに、高精度大規模語彙の音声認識を実現するシステムです。
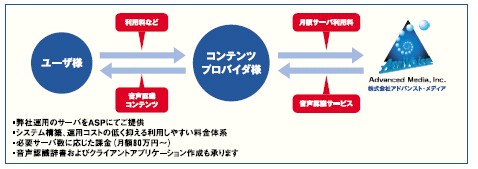
今回サービスを開始します『AmiVoice(R) DSR for Mobile Contents』は音声認識機能のASPサービスで、当社が運用するAmiVoice(R) DSR Serverを、コンテンツプロバイダ様に利用していただくサービスです。コンテンツプロバイダ様は、AmiVoice(R) DSR Clientを組み込んだクライアントアプリを作成するだけで、エンドユーザに対して音声認識機能を利用したコンテンツ提供が可能になります。
【AmiVoice(R) DSRとは】
DSR(Distributed Speech Recognition分散音声認識)は音響分析部だけをクライアント(携帯電話等のモバイルデバイス)サイドに搭載し、メインの認識処理部分はサーバサイドに置くことで、センター型高精度音声認識システムを実現するものです。
DSRでは、音声そのものではなく約1/30に圧縮された、音声認識に必要十分な声の特徴データのみを送信します。音響分析処理は、20MIPS程度の負荷しか端末に要求しません。
特徴データはコンパクトで、8kbps程度の通信速度であっても、ほぼリアルタイムに音声認識が行えます。データ通信時はTCP/IPを使用しますので、これまでの通話をつかった音声認識とは異なり、データ紛失などによる音質の劣化などがまったく発生せず、高精度の音声認識が可能になります。
また、サーバに音声認識データ(言語モデルおよび辞書)を持ちますのでメンテナンスが容易になり、非常に大きな辞書(5万語以上)、言語モデルを複数動作させるようなアプリケーションも実現できます。
【サービスの概要】
◆『AmiVoice(R) DSR for Mobile Contents』
今回発表した製品は、AmiVoice(R) DSRを、携帯電話のコンテンツプロバイダ様に利用していただくためのサービスです。従来のようなコンテンツプロバイダ様自身による、サーバの設置/運用は必要なく、当社にて、設置/運用をいたします。課金につきましても、エンドユーザ様に当社が直接課金することはなく、コンテンツ、サービスを提供されるコンテンツプロバイダ様に対して、定額の利用料をご負担いただきます。
このことにより、コンテンツプロバイダ様は、低い初期投資額と、定額の運用コストで、音声認識機能を利用したコンテンツを提供することが可能になります。
『AmiVoice(R) DSR for Mobile Contents』を利用することにより、操作が難しいダイヤルキー入力の替わりに音声入力を使用できるようになりますので、簡単で、素早く、楽な操作が実現し、コンテンツのユーザーインターフェースが飛躍的に向上します。
また、従来の携帯電話上で利用できるコンテンツは、キー入力が極力少なくなるよう設計されており、それが、ひとつの制約となっていました。その制約をはずせる高精度大規模語彙の音声認識の活用が、携帯電話コンテンツの可能性を広げ、さらには、これまでになかったような携帯電話コンテンツを出現させることが可能となります。
クライアント携帯電話対応機種
・NTT DoCoMo FOMA(R) M1000
・Vodafone 702NK
順次拡充予定
※AmiVoice、およびロゴマークは(株)アドバンスト・メディアの登録商標です。
※記載の会社名および製品名は、各社の登録商標および商標です。
$captions[$StPntr]
$captions[$StPntr]